En este post continúo transcribiendo algunas notas que tomé durante el curso de Human-Computer Interaction del Interaction Design Foundation, cuyo profesor es Alan Dix.
El curso, que recomiendo fuertemente, está en https://www.interaction-design.org/courses/human-computer-interaction.
Este post está relacionado a la temática de la Evaluación, específicamente acerca de tres tipos de conocimiento, y generalizar versus abstraer.
Observación: ¡Las notas las redacté en inglés porque el curso es en inglés!
Espero que les sirvan 🙂
From Data to Knowledge
Three types of knowledge:
- Descriptive knowledge: the way historians explain the past.
- Predictive knowledge: trying to predict what will happen; reasoning from cause to effect. This is often the endpoint of science.
- Synthetic knowledge: when there is a desired endpoint; what cause do I need to to do in order to get to a certain effect. Related to design and engineering. Might be quantitative or qualitative.
Generalisation
Can you ever generalize? Every situation is utterly unique: the same exact test with the same people but on different days will give you different results.
To use past experience is to generalize.
Generalization is not the same as abstraction.
Data on its own does not give you generalization. It can help you generalize, but it does not automatically give you generalization. Generalization always comes from the reasoning and understanding of the data.
From Evaluation to Validation
Is my work good enough? Evaluation is a way to validate your work.
On of the problems is that in reality each user is different and situations are also, there is singularity.
Validating individual products: you can use sampling in order to minimize the effect of singularity. One way of dealing with singularity when conducting usability testing is through sampling.
Generative Artifacts: things that are used to construct something else, like toolkits, devices, interfaces, guidelines or methodologies for example.
Sampling issue becomes very real when evaluating generative artifacts.
Evaluation of generative artifacts on its own is methodologically unsound. If you believe that evaluating generative artifacts gives you a validation, you’re wrong. However, this does not mean that you cannot validate generative artifacts.
Justification
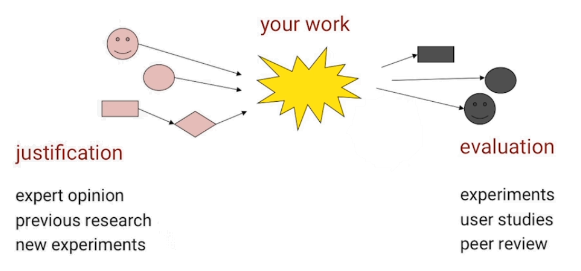
Examples of areas of knowledge:
- Justification is used in mathematics. Mathematicians want to prove if something is true, evaluation is not enough.
- Evaluation is used in Medicine: trying out drugs on animals.
HCI probably sits somewhere between the two.
A lot of generative artifacts must rest in justification because you can’t just evaluate them at all. You can’t prove if an HCI product is correct like you can prove a mathematical theorem. Likewise, if you just try to evaluate an HCI product you will not build real confidence.
The combination of both is usually the best way study an HCI product. When combining them:
- Look for weaknesses in your justification: What are the bits of your argument that are not super strong?
- Use validation to fill in the gaps of your justification.